

Introduction
What is a large language model (LLM) and how can it be used for wildlife conservation and academia? Unless you have been living under a stone for the past few years, you have probably heard about LLMs, but maybe not mentioned as LLM but rather with names like ChatGPT, Apple Intelligence, Gemini, Claude, LLaMA, Mistral, DeepSeek or one of the many other names of proprietary LLM models. In this article I will give you some LLM background (not too technical) followed by use cases centered around wildlife conservation and academia. The use cases are, however, very universal and can easily be modified into other areas and topics.
Some pre words
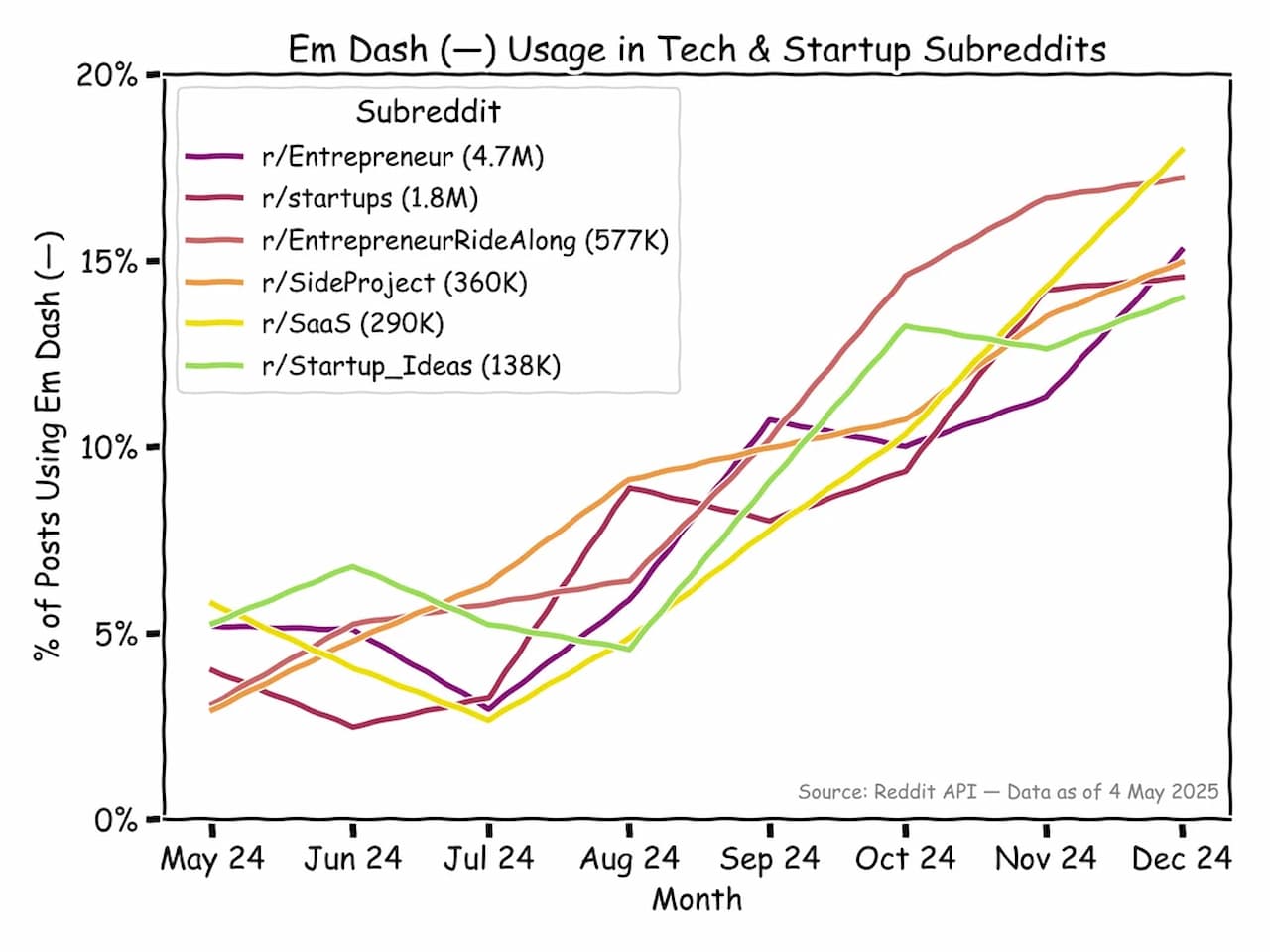
I have seen mixed attitudes around LLMs, even if most of us are using it without knowing it. It’s implemented in our new phones, on our web browsers, we see it used in LinkedIn posts, we see it in email text, and it has really become a part of our everyday. While I do think that it has taken away some “humanity” such as spell errors, like when angles become angels (I hope you are reading this Rebecca 😉) with an LLM that would hardly happen, and we have seen quite the increase of “EM dashes —”in academic papers, LinkedIn posts, reddit forums and mails.
Automate your camera trap image analysis with Animal Detect
Join today to analyze thousands of images in minutes using latest AI models.

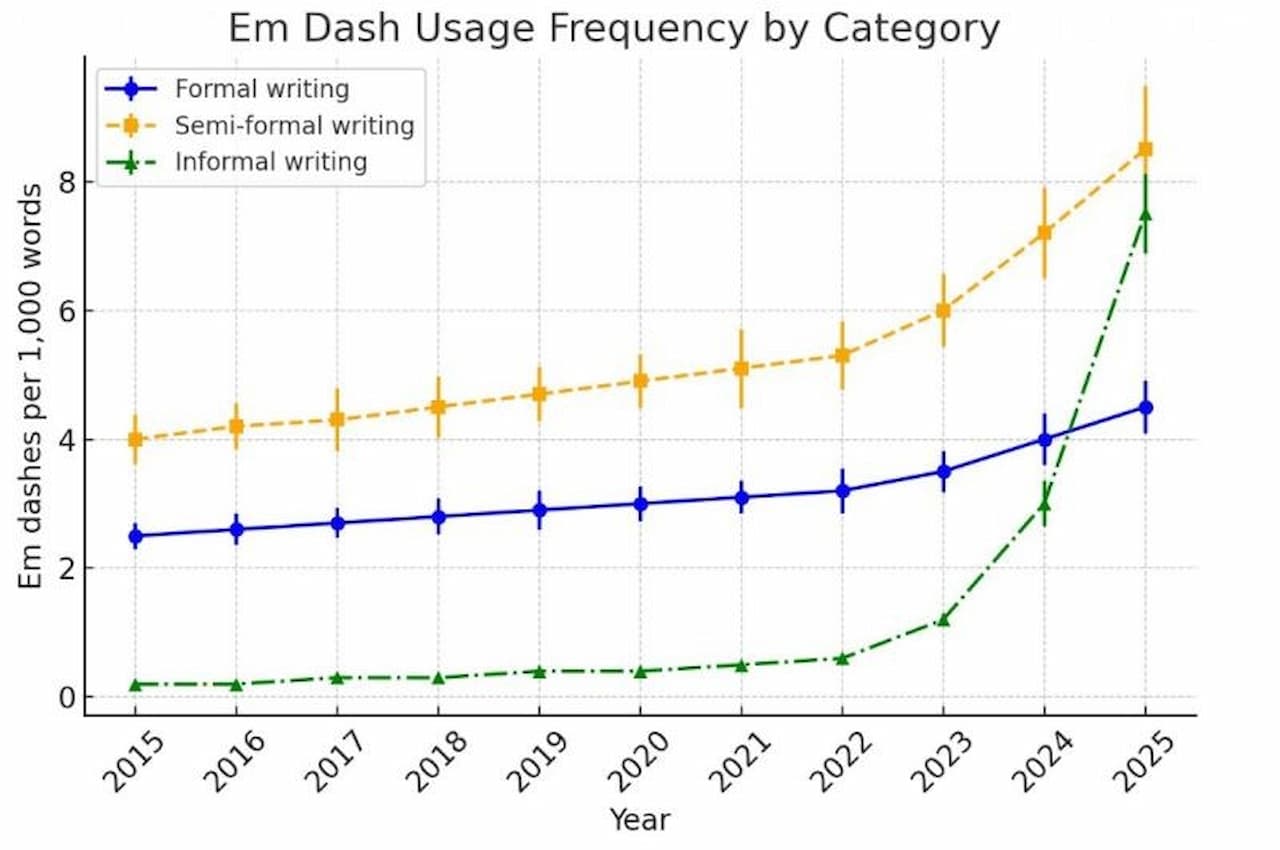
And to no surprise, there has also been an increase in em dashes in ecology abstracts as pointed out here: https://www.pieceofk.fr/the-rise-of-the-em-dash-in-ecology-abstracts/
Maybe the em dashes are stopping, but we have not seen the last of using LLMs in our work and everyday life.
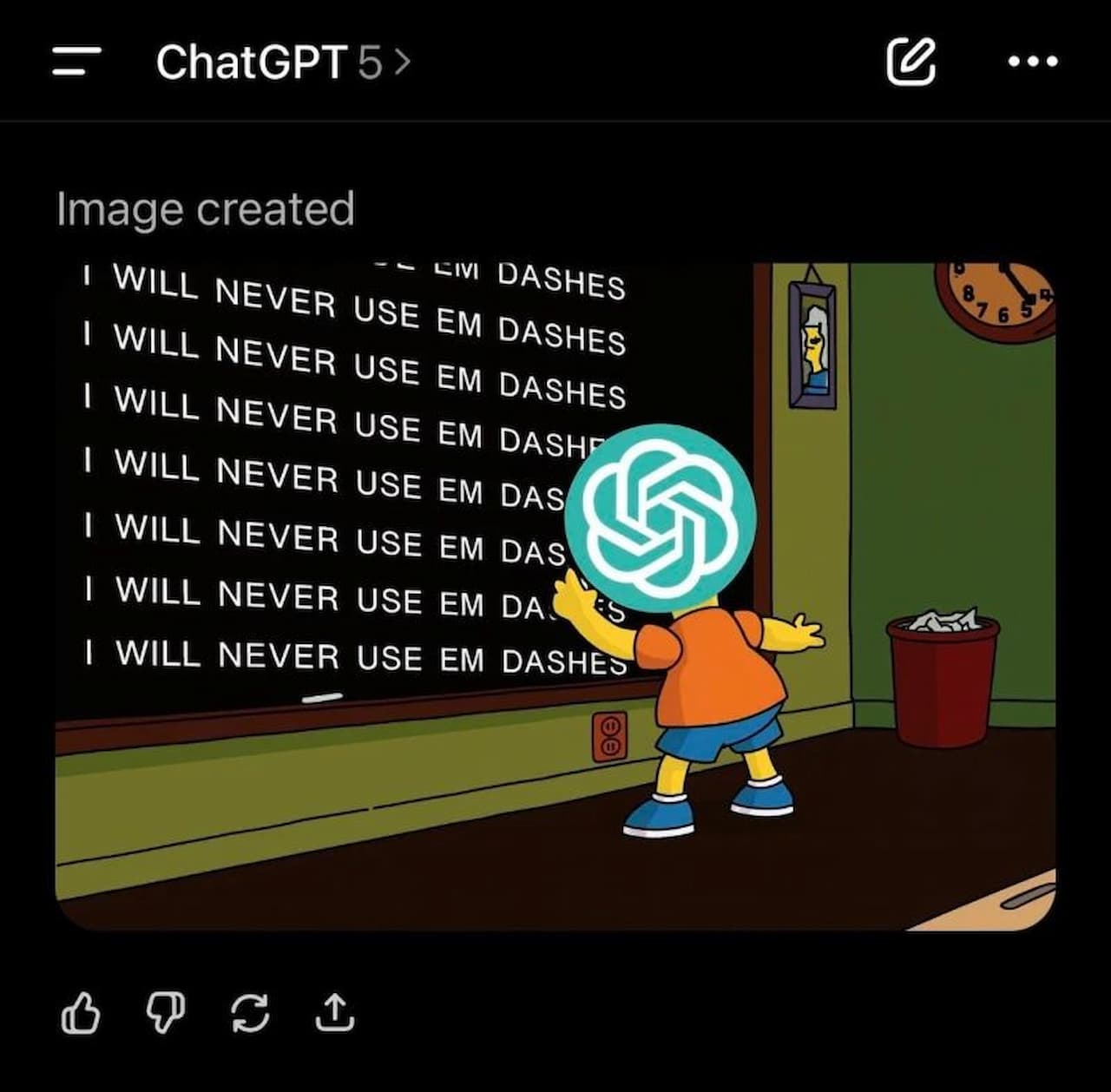
While I love to see more personality (including spell errors) again, and less “GPT”, I am still all for using LLMs! Why? It allows us to be “lazy” and find more ways to optimize what we are doing. I mean, we keep on finding issues and try to find “lazy” solutions. Dishwashers, laundry machines, robot vacuum etc. and it allows us to put our focus elsewhere, and it’s up to us to choose where elsewhere may be. Finding ways to save animals? Writing an academic paper? Taking a well-deserved nap? However, there is a fine line between laziness and stupidness, and I don’t hope I offend someone saying this. Just like you shouldn’t copy + paste a text from Wikipedia in the pre-LLM era (which frankly happened as a peer in our first semester became a bit too lazy), you should not let LLM do everything.
Understanding LLMs
A Large Language Model (LLM) is a type of artificial intelligence model trained on massive amounts of text data to understand and generate human-like language. They are based on neural networks, specifically the transformer architecture (introduced in 2017), which allows them to handle long sequences of text and capture context effectively. GPT-1 (OpenAI) and BERT (Google) were papers published in 2018, where GPT focused on generating texts, and BERT focused on understanding texts. These models were the start of a new era of LLM which most of us use daily, even without knowing about it. Think of LLMs a bit like this: when you type on your phone and it suggests the next word, it is using a small predictive model. It looks at the last few words you wrote and guesses what is most likely to come next. For example, if you type “How are,” it might suggest “you.” These models are simple, trained on limited data, and usually only consider a short bit of context.
LLMs, like GPT or BERT, work on the same basic principle of prediction, but on a much bigger scale. Instead of just a few words, they can consider hundreds or even thousands of words at once. They are trained on massive collections of text from books, articles, and websites, which gives them a much broader understanding of language and the world. Because of this, they can do far more than just suggest the next word. They can write full paragraphs, answer questions, summarize information, or even generate computer code. In practice, there is a lot going on under the hood. One of the most important ideas is the self‑attention mechanism, which allows the model to weigh the importance of each word in relation to all the others in a sentence or passage. This means the model does not just look at words in isolation but understands how they connect across long stretches of text. Thanks to this, LLMs can capture context, meaning, and subtle relationships in language, making their predictions far more accurate and useful than simple word suggestion systems. If you want a visual understanding of how an LLM works or any other AI models, I can strongly recommend the YouTube channel 3Blue1Brown – which helped me during my masters by understanding topics such as back propagation. Here are two links where he explains about LLMs:
https://www.youtube.com/watch?v=wjZofJX0v4M and https://www.youtube.com/watch?v=LPZh9BOjkQs
What is NOT an LLM?
So now ChatGPT and other players can do much more than only generating texts. It can generate an image, and it can also understand context from images which you send to it. The LLM is the text understanding and generation, not more. When we include voice, your voice is transcribed to text, and if your LLM speaks to you, it’s text which has been generated by the LLM and forwarded to a text to speech module. When you send an image you use a Vision Language Model (VLM), which is a model which has feed a lot of images, in combination with texts describing the images, and the model has learned patterns to understand what’s the image contains and some context. If you generate an image, well then you most certainly use a diffusion model, unless you use the early Generative Adversarial Networks (GANs).
I may go in more depth with some of these technologies in future articles, but feel free to learn more about the different technologies if they interest you 😊
Use cases
Your own conservation domain expert!
A single example: Working inside of the conservation area, it’s hard to navigate all the regulations and what to report on. NGOs and organizations often want to document and generate reports on their impact and now we hear more about the term Nature Credits (similar idea to carbon credits). So, reporting and documentation will be more relevant than ever, but what should you report on? And do you have an overview of thousands of pages of relevant data, and what is important for you? Alone an LLM can help you quite well, and point you in the right direction, saving you a ton of time on reporting, but there is something even better! Combining an LLM with RAG (Retrieval-Augmented Generation). RAGs are becoming increasingly popular to be implemented in specific fields to make “experts”, while being able to keep feeding the RAG with the newest and relevant information.
In three simple steps a RAG works like this:
- Retrieve: When you ask a question, the system first searches for a knowledge base (e.g., your company’s documents, a collection of selected EU regulation PDFs, or a database) to find relevant chunks of text.
- Augment: Those retrieved chunks are added to the prompt.
- Generate: The LLM then uses both its own training and the retrieved context to generate a more accurate, grounded answer.
Now, you are probably more creative than me to find other use cases, but the implementation would remain the same.
Vibe coding
What is vibe coding? I like the explanation I found from an article on IBM: “Vibe coding is a fresh take in coding where users express their intention using plain speech and the AI transforms that thinking into executable code. “ I had a love/hate relationship with the term vibe coding for a while, but it has slowly turned more into love in the latest year. You see, just like Danish, English, Japanese or any other language, coding is quite the same. Programming consists of “languages” such as Python, C++, R, etc. Mostly, those languages could be more compared looking at Scandinavia, the Danish, Norwegian and Swedish languages. There are typically a lot of similarities in structure between the programming languages, but they have a hard time understanding one and another. Just like when I first came into Danmark as a Swed :D
So, if an LLM can write a few pages of text in no time, it should be in practice be able to write a few hundred lines of code too. And it does, incredibly well. This allows people with limited knowledge and experience with coding to vibe code some amazing new programs, websites and alike. It does surely help you have experience in coding, as there are still several times where you, the prompt maker, will have to specify for the LLM to give you useful code. How to optimize, run in threads, correctly link input and output paths, and generally a better understanding yourself, will help you debug once the LLM fails.
I use vibe coding for almost everything now, and I will give some personal examples what I have been using it for lately:
- Making Optical character recognition for camera trap images – like this one for Plotwatcher Cameras
- A script to download camera trap images from Lila - which allows the user to specify which of the ~900 species should be downloaded, with possibility to limit the download: Cameratrap Image Downloader
- Setting up a LaTeX environment for my VS Code so I can write my scientific papers directly in my code editor instead of overleaf: https://github.com/AI-EcoNet/VSCode_LaTeX
- A lot of different metadata scripts, where I generate structured JSON files with all of the test data which I am collecting for my first paper.
- Codes related to Animal Detect, where I work mainly on the backend to optimize and improve the overall performance of different AI models.
I would dare to say that I nearly make in average one new python file in average each day, with the help of some vibe coding, and it really helps me to optimize my workflow! Now, if you tried vibe coding with GPT-3 and gave up, well I get you. But things have changed drastically. If you want to vibe code in a code editor, I can strongly recommend Cursor, and maybe your company or institute have already got licenses for co-pilot for VS code, which is also a solid option.
There are also other players, such as windsurf, but I have honestly not got myself to try all the IDE’s with AI support out. If you want to mainly keep yourself out from code editors, I often go to
which allows you to attach more files to a chat than GPT and is a dashboard which has incorporated most of the newest AI models in a nice pink interface. For vibe coding outside of code editors, I often go to Claude 4 Sonnet with High reasoning. Claude seems to be way more generous when outputting code, and can quickly output 1000+ lines of code, whereas I often struggle getting GPT to give me 300 lines of code.
Use LLMs for learning, scraping, researching and criticizing!
LLMs have become my go to when searching for information. Instead of looking through the first few page results on Google results, to get away from sponsored links and irrelevant websites. Instead, the LLM gives what you need, right away.
-
For research, you can ask for help to “scrap” for relevant articles which could be used for inspiration and possibly citation in your own papers. Most LLM models has now got a “search internet” option which will be able to scrap (read through) hundreds of relevant websites, PDFs and articles in seconds, and show you selected sites which it sees as relevant, which at least I have a hard time to compete with that. This has also shown to be extremely helpful in a wildlife conservation context, finding tools, articles and communities which simply does not show up due to SEO or keywords not quite matching with what you search for.
-
Whenever I have a question or feel unsure about some information which I think of, a quick proof check with an LLM can help to see if the information is correct. For example, I wanted to include a story about how “The internet was invented because some Harward professor wanted to monitor a pot of coffee”. Which even in my ears sounded a bit incorrect, but I recall reading somewhere about some coffee pot story from a university and some of it was true. In 1991, researchers at the University of Cambridge (not Harvard) set up a camera pointing at their office coffee pot, using a local network so people could check if the coffee pot was full before walking to the break room. In 1993 they put this feed into the World Wide Web, making it one of the first live web camera (Yes, I took this information from an LLM so I hope it’s correct) I also use it to check up animal taxonomies, which countries I can find different animals and alike, to see if my assumptions are correct.

-
I don’t like LLMs to write everything for me, I have tried to pass my texts through LLMs several times. But I feel like it takes “Hugo” away from the text. However, I sometimes see what it suggests, and make an edit based on it for my own text. I also sometimes ask LLM to criticize what I write and see if anything I write is incorrect. Often when I am on a flow, writing either an article like this or anything else, I love to write uninterrupted, and not stop checking everything I write, until I am done. Often you will see that LLMs are nice to you, and criticizing is by default not the strongest part of an LLM, unless you specifically ask it to do so.
-
For research, I mean literally for everything with the right prompts LLMs are amazing. For example, you are search for the best vacuum cleaner in 2025, you will most likely face 100s of pages of ranking, where most, if not all are sponsored brands. But you want to know what real users have to say. When you ask your LLM to search the internet for forums (such as Reddit) and fair user reviews from for example amazon, and let the LLM do the search, you will most likely get a completely different result. You want to research the interaction between a specific species of animal and a certain fruit from texts, articles and books, let the LLM do the heavy lifting. The LLM is still limited, so you may have to do something manual still 😉
So this are some of the ways I use LLMs myself, in my everyday life, for wildlife conservation and academia. I hope that you can draw some inspiration from this article and start using LLMs even more than you do today!


