
If you didn’t read my attempt to make a very easy introduction to Animal Re-identification for wildlife last week, check it out here: Introduction to Animal Re-identification.
Now it’s time to take a deeeeep dive into the existing solutions and technologies used for re-identification!
Super Quick Recap
Re-identification is the process of distinguishing and recognizing specific individuals within a population. It plays a vital role in wildlife conservation and research. From tracking animals over time to refining population estimates and monitoring health, it’s a powerful tool for understanding and protecting biodiversity.
Automate your camera trap image analysis with Animal Detect
Join today to analyze thousands of images in minutes using latest AI models.

The Current Problem with Re-identification in Wildlife
This part is not purely based on my own experiences like other of my articles, but my research and understanding in challenges with re-identification. I’m pulling insights from the paper on MegaDescriptor, which perfectly outlines some of the biggest challenges. Let’s break them down:
- Inconsistent Methods There’s no standard way to approach re-identification. Researchers use different algorithms, metrics, and datasets, making it hard to compare results or learn from each other’s work.
- Species-Specific Solutions A lot of the current technology is built for specific animals, like tigers or zebras. While that’s great for those species, it’s not very helpful if you’re working with animals where there are no available tools, therefore we need more flexible tools!
- Lack of Large Datasets Good datasets are rare. Collecting and labelling enough images to train reliable models takes a ton of time and effort. As a result, many datasets are small and focused on just one kind of animal, limiting what we can do.
Why This Matters:
Without solving these problems, it’s hard to scale re-identification systems to new species or environments. We need better methods, more adaptable technology, and larger, well-organized datasets to make this work for all kinds of wildlife.
Current Technologies for Animal Re-identification
When it comes to re-identification, different methods are used depending on the dataset, species, and goals of the project. Below are some of the most popular approaches, along with explanations of their concepts:
1. Keypoint Extraction (Local Features)
How It Works: Keypoint extraction identifies unique features in an image (like spots, stripes, or scars) that remain invariant under transformations like rotation, scaling, or lighting changes.
Sometimes it’s easier to show than tellthis figure (borrowed from the Re-Identification of Giant Sunfish paper) illustrates keypoint extraction:
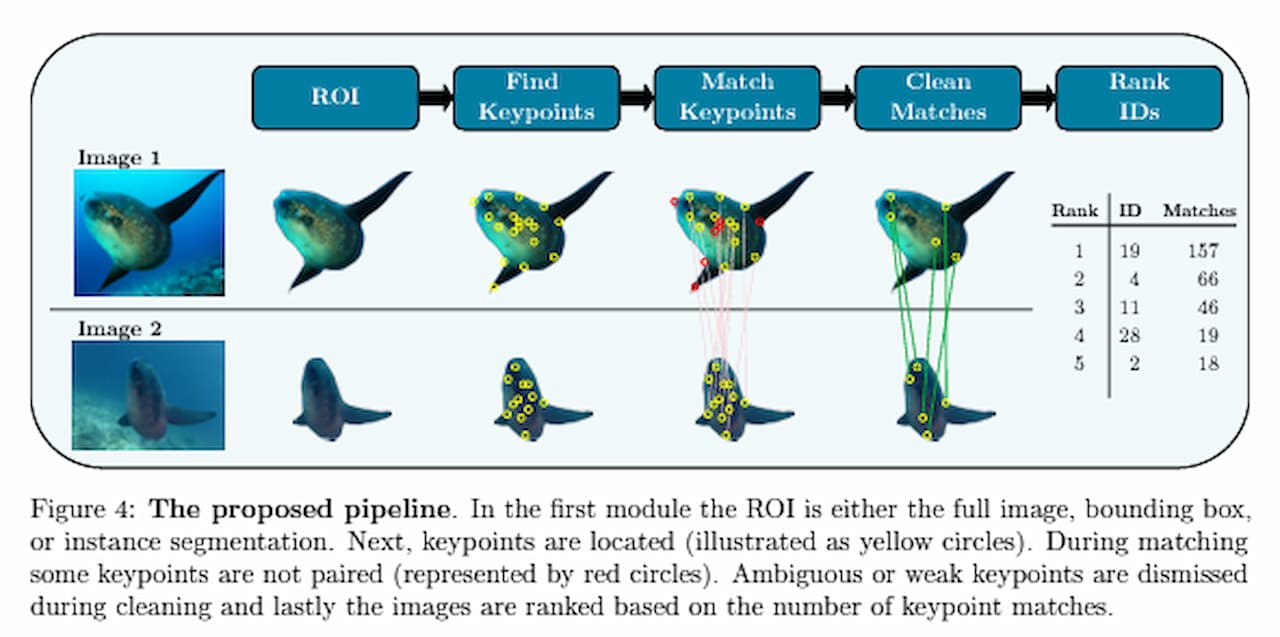
Popular Method: SIFT (Scale-Invariant Feature Transform). It detects interest points and describes them using gradients in small image patches. These descriptors are then matched across images.
Strengths:
- Robust to changes in scale and rotation.
- Works well for patterned animals like zebras or leopards (and sunfish).
Limitations:
- Requires high-quality, close-up images.
- Can struggle with heavily occluded patterns.
Papers using Keypoint Extraction for re-ID :
Re-Identification of Giant Sunfish
2. Pattern Detection (Global Features)
How It Works: For animals with distinctive coats (e.g., tigers or giraffes), earlier methods for re-identification used global pattern analysis. These methods detect regular textures or unique visual markers across the entire image, analyzing frequency and orientation information.
Popular Method: Gabor filters are a classic choice for texture analysis. These filters simulate how the human visual cortex processes texture and orientation. Gabor filters are often used as part of a Convolutional Neural Network (CNN) layer to detect specific patterns and shapes during feature extraction.
Strengths:
- Suitable for animals with repetitive patterns.
- Can analyze large-scale features in full-body images.
Limitations:
- Sensitive to occlusions or lighting changes.
- Less effective compared to modern deep learning-based methods for fine-grained details.
Papers on Pattern Detection:
GaborNet (More general paper and does not going into in animal re-identification)
3. Embeddings in Latent Space (Deep Learning)
How It Works: Deep learning-based methods use convolutional neural networks (CNNs) to map images into a latent space, where similar individuals cluster together based on their shared features. This process often integrates other methods, like pattern detection (e.g., Gabor filters), within the network. However, it introduces challenges, such as the "black box" effect, where the internal workings of CNNs are hard to interpret.
For instance, understanding how individual layers in the network contribute to results can be tricky. Optimizing these systems, whether through fine-tuning, adjusting weights, or changing the network's structure,requires careful experimentation, as the relationships between steps, weights, and outcomes aren’t always transparent.
What Are Embeddings? Embeddings are vectors of numbers that represent an image. These numbers can encode various features, like shape, color, or texture. By comparing the distance and direction between vectors, you can measure similarity between images.
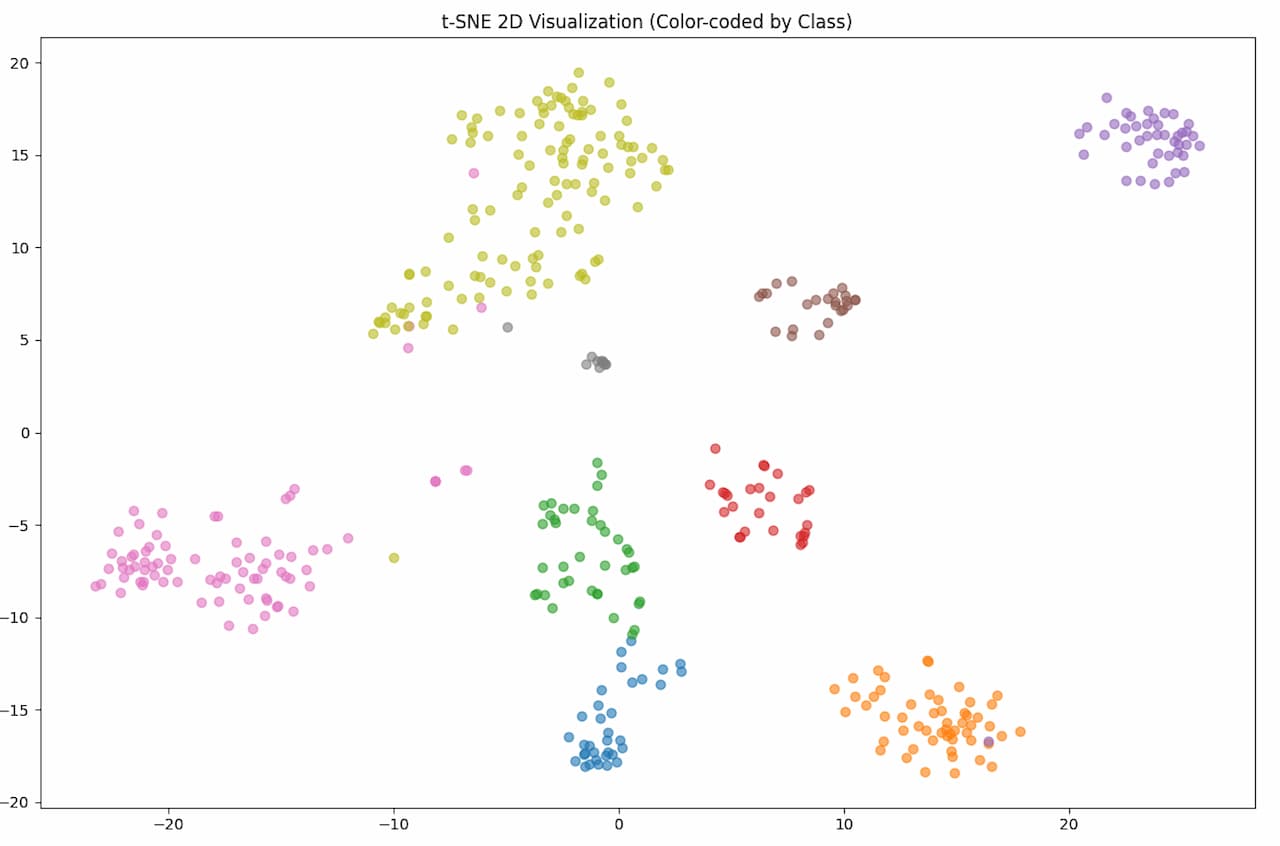
Since embeddings often have thousands of dimensions, it's impossible to visualize them directly. Techniques like t-SNE reduce the dimensions for visualization, creating clusters of similar items. In re-identification tasks, you’d ideally see clusters containing only individuals from the same species, and within those, separate sub-clusters for specific individuals.
To illustrate this, I did a quick test where I grouped embeddings for different animal species. While it wasn’t re-identification per se, the goal was to create distinct clusters. For re-identification, you’d zoom into a specific cluster and begin separating individuals within that group.
Popular Method: Contrastive loss or triplet loss is used during training to ensure embeddings of the same individual are close, while embeddings of different individuals are far apart.
Strengths:
- Scales well to large datasets.
- Adaptable to various species and environments.
Limitations:
- Requires large labeled datasets for effective training.
- The "black box" nature of CNNs makes them difficult to interpret and debug.
Example Tool:
Paper:
WildFusion (Benchmarks against the MegaDescriptor, using a local and a global embeddings)
Commercial Solutions for Animal Re-identification
While open-source tools are powerful, commercial platforms provide ready-made solutions with user-friendly interfaces and species-specific optimizations.
1. African Carnivore Wildbook
What It Does: Tracks and identifies large African carnivores, including lions, cheetahs, and leopards, using AI-based re-identification.
Key Features:
- Automatic detection and matching of individuals based on patterns.
- Centralized database for conservation efforts.
Link: African Carnivore Wildbook
2. Flukebook
What It Does: Focuses on marine species like whales and dolphins, identifying individuals using unique fluke and dorsal fin patterns.
Key Features:
- Uses a blend of manual annotation and AI.
- Supports large-scale oceanic surveys.
Link: Flukebook
3. Spot-A-Shark USA
What It Does: Tracks individual sharks using unique spot patterns and scars.
Key Features:
- Encourages public participation via citizen science.
- Provides visual analytics for shark populations.
Link: Spot-A-Shark
Conclusion
I would strongly recommend pushing the wildlife community to try to find unified methods and tools to help benchmark, compare, and improve the re-identification of animals. Whether it’s commercial or open-source, both types of solutions are crucial as we move toward a future where re-identification becomes an essential tool for conservation efforts.
Re-identification, especially when using methods like embeddings in latent space, holds immense potential. However, challenges like the lack of interpretability, the need for large datasets, and the complexity of deep learning models make it clear that we still have a lot of work to do. I can currently only recommend doing your own research (DYOR) to figure out how these tools work and which methods fit your specific needs.
Personally, I’m always happy to brainstorm or discuss ideas if you need guidance. At this stage, creating a truly global re-identification system remains a distant dream. But it’s a dream I believe is worth pursuing.
While re-identification isn’t something we’re actively developing at Animal Detect right now, we’re approaching every step, building our platform, with the flexibility to possibility adapt and include re-identification in the future. For now, let’s keep experimenting, collaborating, and building tools that empower us to protect wildlife better. Together, we can turn these dreams into reality.


